면접을 위한 CS 전공지식 노트 4장
데이터베이스
데이터베이스 기본
데이터베이스는 일정한 규칙,혹은 규악을 통해 구조화되어 저장되는 데이터의 모음.
해당 데이터베이스를 제어 , 관리하는 통합 시스템을 DBMS라고하며 , 데이터베이스 안에 있는 데이터들은
특정 DBMS마다 정의된 쿼리 언어를 통해 삽입,삭제,조회 등을 수행할 수 있다.
또한 데이터베이스는 실시간 접근과 동시 공유가 가능합니다.
엔티티란 ?
사람 ,장소,물건,사건,개념 여러개의 속성을 지닌 명사를 의미
예) 회원 엔티티 : 이름,아이디,주소,전화번호 속성을 갖습니다.
약한 엔터티와 강한 엔터티란 ?
예를 들어 A가 혼자서는 존재하지 못하고 B의 존재 여부에 따라 종속적이라면 A는 약한 엔터티이고 B는 강한
엔터티가 됩니다. 예) 방은 건물안에만 존재할 수 있기떄문에 방은 약개체 건물은 강개체
릴레이션이란?
데이터베이스에서 정보를 구분하여 저장하는 기본단위
엔터티에 관한 데이터를 데이터베이스는 릴레이션 하나에 담아서 관리합니다.
릴레이션을 다른말로 데이터베이스에서는 "테이블"이라고 한다. NoSQL에서는 컬렉션이라고 한다.
테이블과 컬렉션
데이터베이스는 크게 관계형 데이터베이스와 NOSQL 데이터베이스로 나눌 수 있다.
MYSQL은 레코드 - 테이블 - 데이터베이스로 이루어져 있고 MongoDB 데이터베이스의 구조는
도큐먼트-컬렉션-데이터베이스로 이루어져 있다.
속성
속성은 릴레이션에석 관리하는 구체적이며 고유한 이름을 갖는 정보,
예) 차 엔티티의 속성은 car_id,car_wheel_count,car_color,car_type등
도메인
도메인이란 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합을 말합니다.
예를 들어 성별이라는 속성이 있다면 이 속성은 남,여라는 집합을 갖게 된다.
필드와 레코드

DATE ,DATETIME,TIMESTAMP차이
DATE: 날짜부분은 있지만 시간부분은 없는 값 1000-01-01~9999-12-31
DATETIME: 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
TIMESTAMP: 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07
Timestamp 타입을 갖는 쿼리는 캐시로 저장되나 Datetime 타입을 갖는 쿼리는 캐시로 저장되지 않는다.
또한 DATETIME은 8바이트. TIMESTAMP는 4바이트다.
CHAR 와 VARCHAR
CHAR(30)이라면 최대 30글까지 입력할 수 있다.
VARCHAR는 가변길이 문자열 0~65535사이 값으로 지정가능
TEXT BLOB
TEXT: 큰 문자열 저장에 쓰며 주로 게시판의 본문에 사용
BLOB:이미지,동영상 등 큰 데이터 저장 하지만 보통은 aws s3 스토리에 저장하고 파일 경로를 VARCHAR로 함
ERD와 정규형
ERD는 시스템의 요구사항을 기반으로 작성되며 이 ERD를 기반으로 데이터베이스를 구축합니다.
ERD는 관형 구조로 표현할 수 있는데 구성하는데 유용하지만, 비정형 데이터를 구성하는데 충분히 표현할 수 없다.
- 비정형 데이터란?
비구조화 데이터를 말하며, 미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 정리되지 않은 정보
정규화과정
정규화과정은 릴레시연 간의 잘못된 종속관계로 인해 데이터베이스 이상현상이 일어나는 것을 해결하거나,
저장 공간을 효율적으로 사용하기 위해 릴레이션을 여러 개 분리하는 과정,
데이타베이스 이상현상이란 ?
회원이 한 개의 등급을 가져야 하는데 세 개의 등급을 갖거나 삭제할 때 필요한 데이터가 같이 삭제되고,
데이터를 삽입해야하는데 하나의 필드 값이 NULL이 되서 삽입이 어려운 현상을 말합니다.
정규형 원칙
- 자료의 중복성은 감소, 독릭적인 관계는 별개의 릴레이션으로 표현해야하며,각각의 독립적인 표현이 가능해야한다.
제1정규형
- 릴레이션의 모든 도메인이 더 이상 분해될 수 없는 원자 값만으로 구성되어야 합니다.
속상 값 중에서 한개의 기본키에 대해 두개 이상의 값을 가지는 반복 집합이 있어서는 안됩니다.
만약에 반복된 집합이 있다면 제거해야함
제2정규형
- 제1정규형을 만족하며 부분 함수의 종속성을 제거한 형태
부분함수의 종속성 제거란 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속이여야 한다.

제3정규형
제2정규형을 만족하고 기본키가 아닌 모든 속성이 이행적 함수 종속을 만족하지 않은 상태여야한다.
이행적함수종속이란 ? A->B->C
유저ID 등급 할인율
홍철 플래티넘 10%
민우 골드 30%
건우 실버 50%
-> 제3정규형 시
-----------------------
홍철 픞래티넘
-----------------------
플래티넘 할인율 10%
이런식으로 나눈다.
트랜잭션과 무결성
트랜잭션은 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업의 단위를 말하며 데이터베이스에 접근하는 방법은 쿼리이므로,
ㅡㄱ 여러개의 쿼리들을 하나로 묶는 단위입니다.
트랜잭션 특징
ACID - 원자성,일관성,독립성,지속성
원자성 - 트랜잭션과 관련된 일이 모두 수행되거나 되지 않았거나를 보장하는 특징
일관성- 하나의 트랜잭션 이전과 이후,데이터베이스의 상태는 이전과 같이 유효해야한다.
격리성- 트린잭션 수행 시 서로 끼어들지 못해야한다. 서로 격리되어 순차적으로 실행되어야 한다.
지속성- 트랜잭션이 커밋이 된 데이터를 그 이후에도 로그 기록이 남아있어야 한다.
격리수준 - SERIALIZABLE,REPEATABLE_READ,READ_COMMITTED,READ_UNCOMMITTTED
REPEATABLE_READ : 팬텀리드
READ_COMMITTED: 팬텀리드, 반복 가능하지 않은 조회가 발생함
READ_UNCOMMITTED 팬텀리드, 반복 가능하지 않은 조회, 더티리드가 발생할 수 있다.
격리수준에 따라 발생하는 형상
격시 수준에 따라 ㅂ라생하는 현상은 팬텀리드,반복가능하지않은 조회, 더티 리드가 있습니다.
팬텀리드란 ?
트랜잭션내에서 동일한 쿼리를 보냈을 때 해당 조회 결과가 다른경우를 의미합니다.
ex) 사용자 A가 회원 테이블에서 age가 12이상인 회원들을 조회하는 쿼리를 보낸다고 해봅시다.
이결과로 세개의 테이블이 조회한다고하보죠. 그다음 사용자 B가 age가 15인 회원 레코드를 삽입합니다.
그러면 그다음 세 개가 아닌 네 개의 테이블이 조회가 됩니다.
반복 가능하지 않은 조회(Non-Repeatable Read)
반복가능하지않은 조회: 한 트랜잭션 내의 같은 행에 두번 이상 조회가 발생했을 때 그 값이 다른경우
ex) 사용자 A가 민우의 보석 개수가 100개라는 값을 가진 데이터였는데 그 이후 사용자 B가 그 값을 1로 변경
해서 커밋했다고 하면 사용자 A는 100이 아닌 1을 읽게된다.
더티리드
반복가능하지않은 조회와 유사하며 한 트랜잭션이 실행 중 일때 다른 트른잭션에 의해 수정되었지만 아직
"커밋되지 않은" 행의 데이터를 읽을 수 있을 때 발생합니다.
ex) 사용자 A가 민우의 보석개수를 100을 1로 변경한 내용이 "커밋되지 않은"상태라도 그 이후 사용자
B가 조회한 결과가 1로 나오는 경우
격리수준
SERIALIZABLE
말 그대로 트랜잭션을 순차적으로 진행시키는 것을 말한다. 여러 트랜잭션이 동시에 같은 행에 접근할 수 없다.
이 수준은 매우 엄격한 수준으로 해당 행에 대해 격리시키고, 이후 트랜잭션이 이 행에 대해 일어난다면 기다려야한다.
그렇기 떄문에 교착상태가 일어날 확률이 많고 가장 성능이 떨어지는 격리 수준입니다.
REPEATABLE_READ
MYSQL의 innodb 기본값 하나의 트랜잭션이 수정한 행을 다른 트랜잭션이 수정할 수 없도록 막아주지만
새로운 행을 추가하는 것은 막아주지 않는다. 따라서 이후에 추가된 행이 발견될 수 있다. 하지만 INNODB는 팬텀리드가 발생하지않는다
READ_COMMITTED
가장 많이 사용하는 격리수준이며 PostrgreSQL,SQL Server,Oracle에서 기본값으로 셋팅되어있음
READ_UNCOMMITTED와는 달리 다른 트랜잭션이 커밋하지 않은 정보를 읽을 수 없다. 즉 , 커밋이 완료된
데이터에 대해서만 조회를 허용, 하지만 어떤 트랜잭션이 접근한 행을 다른 트랜잭션이 수정할 수 있다.
READ_UNCOMMITTED
가장낮은 격리수준,하나의 트랜잭션이 커밋되기 이전에 다른 트랜잭션에 노출되는 문제가 있다.
하지만 속도가 제일빠름, 거대한 양의 데이터를 "어림잡아"집계하는데 사용하면 괜찮다.
지속성
성공적으로 수행된 트랜잭션은 영원히 반영되어야한다. 데이터베이스 시스템 장애가 발생해도 원래 상태로
복구하는 회복 기능이 있어야 함 .데이터베이스는 이를위해 저널링,체크썸,롤백기능을 제공
체크섬:오류 정정을 통해 송신된 자료의 무결성보호
저널링: 데이터베이스에 변경사항을 커밋하기 전 로킹하는 것. 트랜잭션 등 변경 사항에 대한 로그는 남기는 것
무결성
- 하나의 트랜잭션이 성공적으로 수행되었다면, 해당 트랜잭션에 대한 로그가 남아야하는 성질
https://alexander96.tistory.com/55?category=1065003
Serializable로 동시성을 잡으려 하면 데드락을 만납니다
최근 우연찮은 기회로 현업 개발자와 동시성 이슈에 대한 얘기를 할 기회를 얻었다. 동시성 이슈에 대해서 고민해보고 어떤 상황에 어떤 방식으로 해결하는 결론을 내렸는 지 정리된 걸 얘기해
alexander96.tistory.com
Serializable은 팬텀 리드 문제를 해결하기 위해서만 사용한다.(mysql의 InnoDB 엔진일 경우 Repeatable Read만 되어도 팬텀 리드가 발생하지 않는다.) 사실 거의 사용할 일 없다. 동시성을 잡는다고, Serializable의 락 기능을 이용해보겠다고 그걸 걸었다간… 더 어려운 문제를 맞이할 수 있다.
데이터베이스 종류
관계형 데이터베이스
행과 열을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스를 가르키며 SQL이라는 언어를 써서 조작합니다.
MYSQL, PostgreSQL,Oracle,SQL Server,MSSQL 등이 있습니다.

왜 사람들은 InnoDB를 사용할까 ?
MyISAM VS InnoDB
Mysql의 스토리지 엔진으로 가장 많이 사용하는 MyISAM(발음하기 힘드네... 마이아이삼,마이아이샘), InnoDB의 차이를 알아보자.
결론적으로 얘기하자면 트랜잭션 처리가 필요하고 대용량의 데이터를 다루기 위해서는 InnoDB가 효율적이고, 반면 트랜잭션 처리가 필요없고 운영에 Read only 기능이 많은 서비스일수록 MyISAM 엔진이 효율적이다.
한마디로 MyISAM은 SELECT가 많은서비스에, InnoDB는 데이터의 변화가 많은 서비스에 적합하다 할 수 있다.
1. MyISAM
MyISAM은 항상 테이블에 ROW COUNT를 가지고 있기 때문에 SELECT count(*) 명령시 빠르고,
SELECT 명령시에도 빠른 속도를 자랑한다. 또한, 풀텍스트 인덱스를 지원하는데
여기서 풀텍스트 인덱스는 검색 엔진과 유사한 방법으로 자연 언어를 이용해 검색할 수 있는 특별한 인덱스로 모든 데이터 문자열의 단어를 저장한다.
그렇기 때문에 Read Only기능이 많은 서비스일 수록 MyISAM엔진이 효율적이라 할 수 있다.
단점으로는, row level locking을 지원하지 못해, select insert update delete시 해당 Table 전체에 Locking이 걸린다.
(row의 수가 커지면 커질수록 속도는 엄청나게 느려진다는 단점!)
2. InnoDB
장점으로는... MyISAM의 단점으로 있었던 row level locking이 지원된다. 그렇기 때문에 트랜잭션 처리가 필요한 대용량의 데이터에 유리한 점이 있어서, 뭐 예를 들자면 사용자의 CRUD가 많은 서비스에 유리할 것 같다 (필자가 담당하고있는 서비스의 대부분의 스토리지 엔진도 InnoDB인데)
단점으로는, MyISAM의 장점인 풀텍스트 인덱스를 지원하지 못한다고 한다.
Nosql 데이터베이스
mongodb
mongodb는 json을 통해 데이터에 접근할 수 있고, Binary JSON 형태로 데이터가 저장되며 와이어드타이거 엔진이 기본 스토리지 엔진으로 장착된 키-값 데이터 모델에서 확장된 도큐먼트 기반의 데이터베이스입니다. 확장성이 뛰어나며, 빅데이터 를 저장할 때 성능이 좋고 고가용성 샤딩, 레플리카셋을 지원합니다. 또한 스키마를 정해 놓지 않고 데이터를 삽입할 수 있기 때문에 다양한 도메인의 데이터베이스를 기반으로 분석하거나 로깅 등을 구현할 때 강점을 보입니다.
또한 MongoDB는 도큐먼트를 생성할 때마다 다른 컬렉션에서 중복된 값을 지니기 힘든 유니크한 값인 ObjectID가 생성됩니다.

기본키는 유닉스 시간 기반의 타임스탬프(4바이트),랜덤 값(5바이트),카운터(3바이트)로 이루어져 있습니다.
Redis
redis는 인메모리 데이터베이스이자 키-값 데이터 모델 기반의 데이터베이스
기본적인 데이터 타입은 문자열이며 최대 512MB까지 저장할 수 있습니다. 이외에도 Set,Hash등을 지원
pub/sub 기능을 통해 채팅시스템, 데이터베이스 앞단에 두어 캐싱계층,단순한 키 - 값이 필요한 세션정보관리,
정렬된 셋(sorted set)자료구조를 이용하여 실시간 순위표 서비스에 사용됩니다.
인덱스
인덱스의 필요성
인덱스는 데이터를 빠르게 찾을 수 있는 하나의 장치

책의 본문이 있고 그 본문 안에 내가 찾고자 하는 "항목"을 찾아보기를 통해 빠르게 찾을 수 있다.
B-TREE
인덱스는 B-TREE라는 자료구조로 이루어져 있다. 이는 루트노드,인터널노드,리프노드로 나뉩니다.

트리탐색은 맨위 루트노드부터 탐색이 일어나며 브랜치노드(인터널노드)를 거쳐 리프노드까지 내려옵니다. 57보다 같거나 클때까지 <=를 기반으로 처음 루트노드에서 39.83이후 아래 노드로 내려와 46,53,57등 정렬된 값을 기반으로 탐색을 합니다. 이렇게 루트노드부터 시작하여 마지막 리프 노드에 도달해서 57이 가리키는 데이터 포인터를 통해 결과값을 반환합니다.
B-tree 와 B+tree의 차이
| B-tree | B+tree | |
| 주요 특징 | 모든 내부, 리프 노드들이 데이터를 가진다 | 단지 리프노드만 데이터를 가진다 |
| 검색 | 모든 키가 리프에서 사용가능 하지 않기 때문에, 검색이 때로 느리다 | 모든 키가 리프 노드에 있기 때문에 검색이 빠르고 정확하다 |
| 중복 키 | 트리에 중복키가 없다 | 중복키가 존재하며 모든 데이터들은 리프에 있다 |
| 삭제 | 내부 노드의 삭제는 목잡하고 트리 변형이 많다 | 어떠한 노드든 리프에 있기 때문에 삭제가 쉽다 |
| 리프노드 | 링크드 리스트로 저장되지 않는다 | 링크드 리스트로 저장된다 |
| 높이 | 특정 갯수의 노드는 높이가 높다 | 같은 노드일 때 B-tree보다 높이가 낮다 |
| 사용 | 데이터베이스, 검색엔진 | 멀티레벨 인덱스, DB 인덱스 |
b+트리가 빠른이유 : B+ 트리에서는 내부 노드는 키만을 저장하며, 데이터는 리프 노드에만 저장됩니다. 이는 더 많은 키를 저장할 수 있도록 하며, 캐시의 효율성을 향상시킵니다.
Mysql 인덱스를 만드는 방법
MySQL의 경우 클러스터형 인덱스와 세컨더리 인덱스가 있으며, 클러스터형 인덱스는 테이블 당 하나를 설정할 수 있다.
primary key 옵션으로 기본키로 만들면 클러스터형 인덱스를 생성할 수 있다. 기본키로 만들지 않고 unique not null옵션을
붙이면 클러스터형 인덱스로 만들 수 있다.
create index ... 명령어 기반으로 만들면 보조인덱스(세컨더리 인덱스)를 만들 수 있다. 하나의 인덱스만 생성할 것이라면
클러스터형 인덱스를 만드는 것이 세컨더리 인덱스를 만드는 것 보다 성능이 좋다.
세컨더리 인덱스는 보조 인덱스로 여러개의 필드 값을 기반으로 쿼리를 많이 보낼 때 생성해야합니다.
ex) age라는 하나의 필드만으로 쿼리를 보낸다면 클러스터형 인덱스만 필요하겠죠 ? 하지만 age,name,email등등이
where 조건문에 타게되면 다양한 필드를 기반으로 쿼리를 보낼 것이고 세컨더리 인덱스를 사용해야합니다.
but , 하지만 중복도가 낮은( 카디널리티가 높은 것) 을 기반으로 인덱스를 설정해야합니다.
카디널리티가 높을 때 index를 왜 더 잘탈까 ?
- 검색 속도 향상: 카디널리티가 높을수록 각 값이 더 분산되어 있기 때문에 특정 값을 찾을 때 인덱스를 사용하는 것이 더 효율적입니다. 만약 열의 값이 대부분 중복되는 경우 인덱스를 사용하더라도 해당 값이 나타나는 레코드가 많아서 검색이 느려질 수 있습니다.
- 인덱스 크기 관리: 카디널리티가 낮은 열에 인덱스를 만들면 인덱스 크기가 커질 수 있습니다. 하지만 카디널리티가 높은 열에 인덱스를 만들면 인덱스 크기가 상대적으로 작아지고 메모리를 효율적으로 사용할 수 있습니다.
인덱스를 최적화하는방법
inflearn강의 듣는거에서 추가보충하자 추후 **********
1. 항상 테스팅하라
인덱스 최적화 기법은 서비스 특징에 따라 달라진다, 서비스에서 사용하는 객체의 깊이,테이블의 양등이 다 다르기 때문
explain을 통해 실행계획을 분석하고 내 인덱스가 몇퍼센트 타고있고 몇개의 row 수를 가지고있고 몇 ms가 나오는지 비교를 하고 테스팅하여 걸리는 시간을 최소화해야합니다.
2. 복합인덱스는 같음,정렬,다중값,카디널리티 순이다
보통 여러필드를 기반으로 조회할 때 복합 인덱스를 생성하는데 , 이 인덱스를 생성할 때는 순서가 있고 생성순서에 따라
인덱스 성능이 달라집니다. 같음,정렬,다중 값, 카디널리티 순으로 생성해야한다.
1. 어떠한 값과 같음을 비교하는 ==이나 equals이라는 쿼리가 있다면 제일 먼저 인덱스로 설정한다.
2. 정렬에 쓰는 필드라면 그 다음 인덱스로 설정합니다.
3. 다중 값을 출력해야 하는 필드 , 즉 쿼리 자체가 > 이거나 < 등 많은 값을 출력해야 하는 쿼리에 쓰는 필드라면 나중에 인덱스를 설정합니다.
4. 유니크한 값의 정도를 카디널리티라고 합니다. 이 카디널리티가 높은 순서를 기반으로 인덱스를 생성해야 합니다.
예를 들어 age와 email이 있다고 합시다. 어떤 것이 더 높죠? 당연히 email입니다. 즉 ,email이라는 필드에 대해 인덱스를 먼저 걸어야한다.
조인의 종류
내부조인(inner join):
select * from tableA a
inner join tableB b on
A.key = B.key
왼쪽조인(left outer join):
select * from tableA a
left outer join tableB b on
A.key = B.key
오른쪽 조인(right outer join):
select * from tableA a
right outer join tableB b on
A.key = B.key
합집합 조인(full outer join):
select * from tableA a
full outer join tableB b on
A.key = B.key
조인의 원리
조인의 원리인 중첩 루프 조인, 정렬 병합 조인, 해시 조인이 있다.
중첩루프조인
- Nested Loop Join은 중첩 for문과 같은 원리로 조건에 맞는 조인을 하는 방법, 랜덤 접근에 대한 비용이 많이 증가하므로 대용량 테이블에서는 사용하지 않습니다. 기본적으로 MySQL에서 사용하는 조인방법

정렬 병합 조인
테이블을 조인할 필드 기준으로 정렬하고 정렬이 끝난 이후에 조인 작업을 수행하는 조인, 조인할 때 쓸 적절한 인덱스가 없고 대용량의 테이블들을 조인하고 조인 조건으로 <,> 등 범위 비교 연산자가 있을 때 씁니다.
해시 조인
해시조인은 해시 테이블을 기반으로 조인하는 방법 두개의 테이블을 조인한다고 했을 때 하나의 테이블이 메모리에 온전히 들어간다면 보통 중첩 루프 조인보다 더 효율적입니다.(메모리에 올릴 수 없을 정도로 크다면 디스크를 사용하는 비용이 발생합니다) 또한 동등조인에서만 사용할 수 있습니다.
MySQL의 경우 8.0.18 릴리스와 함께 이 기능을 사용할 수 있게 되었으며 이를 기반으로 해시조인의 과정을 살펴보겠습니다.
빌드단계
빌드 단계는 입력 테이블 중 하나를 기반으로 메모리 내 해시 테이블을 빌드하는 단계
예를들어 persons 와 countries라는 테이블을 조인한다고 했을 때 둘 중에 바이트가 더 작은 테이블을 기반으로해서 테이블을 빌드합니다.
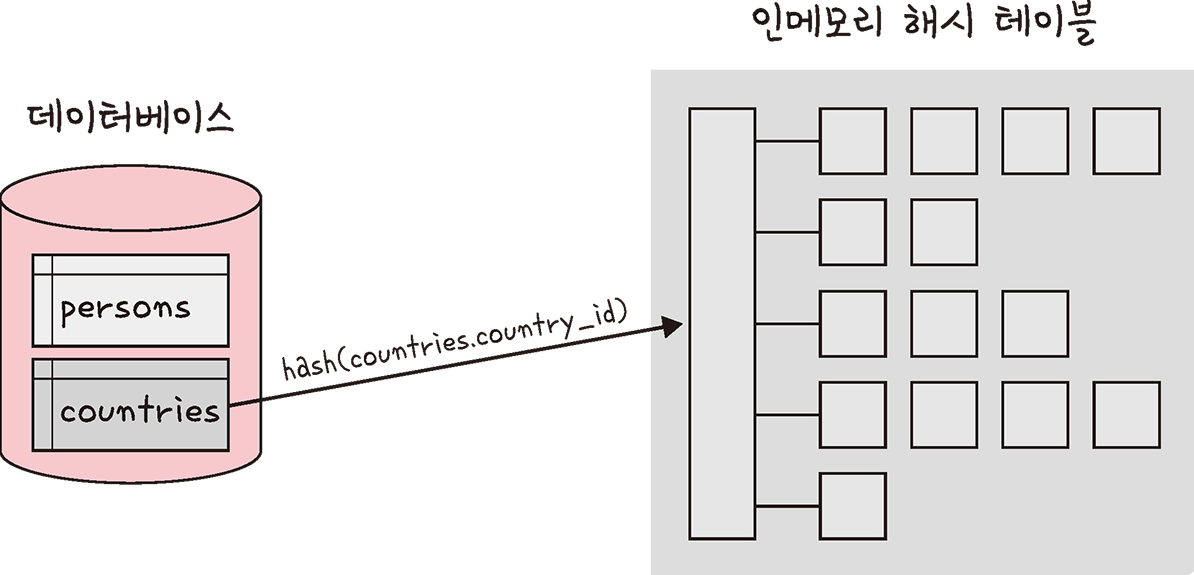
또한, 조인에 사용되는 필드가 해시 테이블의 키로 사용됩니다.countires_country_id 가 키로 사용된다.
프로브단계
프로브 단계 동안 레코드 읽기를 시작하며, 각 레코드에서 persons_country_id에 일치하는 레코드를 찾아서 결과값으로 반환
이를 통해 각 테이블은 한번 씩만 읽게 되어 중첩해서 두개의 테이블을 읽는 중첩 루프 조인보다 보통은 좋은 성능을 가짐.