CKA 실전 문제 & 명령어 정리
📦 Pod 관련 명령어
🟡 1. 파드 갯수 확인 (namespace가 없으면 default로)
kubectl get pods -n <namespace>
kubectl get pods # default 네임스페이스🟡 2. Nginx 이미지를 사용하는 파드 생성
kubectl run nginx --image=nginx🟡 3. 파드가 어떤 이미지로 생성되었는지 확인
kubectl describe pod <pod-name>🟡 4. 파드의 상세 정보 확인 (Node, IP 등 포함)
kubectl get pods -o wide🟡 5. 파드 삭제
kubectl delete pod <pod-name>
⚙️ YAML을 이용한 Pod 생성 및 수정
🟡 6. 잘못된 이미지로 Pod 생성 (Dry-run & YAML 저장)
kubectl run redis --image=redis123 --dry-run=client -o yaml > redis.yaml🟡 7. 이미지 수정 후 재적용
vi redis.yaml # 이미지명 redis 로 수정
kubectl apply -f redis.yaml🔁 ReplicaSet 관련
🟡 8. ReplicaSet
kubectl create -f replicaset.yaml🟡 9. 이미지 수정 후 기존 파드 삭제
kubectl edit rs <replica-set-name> # image 수정 kubectl delete pod <pod1> <pod2> ...🟡 10. ReplicaSet 스케일 조정
kubectl scale rs <replica-set-name> --replicas=5🚀 Deployment 관련
🟡 11. Deployment 생성
kubectl create deployment httpd-frontend --image=httpd:2.4-alpine --replicas=3kubectl create -f /root/deployment-definition-1.yaml # Kind: Deployment 로 수정 필요🌐 서비스 (Service) 관련
🟡 12. 서비스 확인
kubectl get svc
kubectl get service🟡 13. NodePort 서비스 YAML 예시
apiVersion: v1
kind: Service
metadata:
name: webapp-service
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 30080
selector:
name: simple-webapp📂 Namespace / Label / Selector
🟡 14. finance 네임스페이스에 Pod 생성
kubectl run redis --image=redis -n finance🟡 15. 모든 네임스페이스의 파드 조회
kubectl get pods --all-namespaces🟡 16. 라벨 셀렉터를 사용한 파드 조회
kubectl get pods -l env=dev
kubectl get pods -l bu=finance
kubectl get all -l env=prod
kubectl get all -l env=prod,bu=finance,tier=frontend
🖥️ 노드 및 스케줄링
🟡 17. 노드 목록 확인
kubectl get nodes🟡 18. 노드 상세 정보 확인
kubectl describe node <node-name>🟡 19. 노드에 Taint 설정 및 제거
kubectl taint nodes node01 spray=mortein:NoSchedule
kubectl taint nodes controlplane node-role.kubernetes.io/control-plane:NoSchedule-🟡 20. 노드에 Label 부여
kubectl label node node01 color=blue
📌 Node Affinity 설정 예시 (Deployment 내에)
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: color
operator: In
values:
- blue위 코드는 Deployment의 template.spec 안쪽에 작성되어야 함
부가 정보
| ClusterIP | 클러스터 내부 | http://<service-name>.<namespace>.svc.cluster.local |
| NodePort | 외부 접근 가능 | http://<NodeIP>:<NodePort> |
🟡 21. default 스케줄러 확인

🟡 21. 스케줄러 이미지 확인
kubectl describe pod kube-scheduler-controlplane -n kube-system
🟡 21. ConfigMap 생성
kubectl create configmap my-scheduler-config --from-file=/root/my-scheduler-config.yaml -n kube-system
kubectl get configmap my-scheduler-config -n kube-system
NAME DATA AGE
my-scheduler-config 1 5s🧠 요약
| 스케줄러 | 파드를 어떤 노드에 띄울지 결정하는 쿠버네티스 컴포넌트 |
| ConfigMap | 설정 데이터를 외부에서 관리하고 파드에 주입할 수 있는 객체 |
🟡 22. 스케줄러 이미지 설정
kubectl describe pod kube-scheduler-controlplane -n kube-system | grep image
Normal Pulled 23m kubelet Container image "registry.k8s.io/kube-scheduler:v1.32.0" already present on machine스케줄러 컨트롤 플레인 이미지 가져와서 yaml파일에 설정하기
🟡 23. 일반파드에 커스텀 스케줄러 적용

🟡 24. admission-plugins
kubectl exec -it -n kube-system kube-apiserver-controlplane -- kube-apiserver -h | grep 'enable-admission-plugins'
admission-plugins란?
- Kubernetes API Server에 붙는 후킹 시스템
- 클러스터 내 리소스에 대한 요청(create/update 등)을 가로채서 검증(Validating) 하거나 변경(Mutating) 함
- 사용자 요청을 클러스터에 반영하기 전에 정책을 강제하거나, 자동 설정을 적용 가능
📂 자동 프로비저닝 시나리오 (예시)
예를 들어 Namespace가 생성될 때 다음 리소스를 자동으로 같이 만들고 싶다고 할 때:
- ResourceQuota
- LimitRange
- Default NetworkPolicy
- ConfigMap, Secret 등
이를 위해 사용할 수 있는 주요 admission-plugin 종류는:
✅ MutatingAdmissionWebhook
- 리소스가 생성되기 전이나 도중에 내용을 변경 가능
- 예: Namespace 생성 시, 자동으로 Label 추가, 기본 ResourceQuota 설정 삽입 등
✅ ValidatingAdmissionWebhook
- 리소스가 생성되기 직전에 검증만 수행, 변경은 못 함
- 예: 정책에 맞지 않는 Pod 생성 차단
🟡 25. What is the flow of invocation of admission controllers?
- First Mutating and Validate
🟡 26. Create namespace webhook-demo where we will deploy webhook components
kubectl create ns webhook-demo
🟡 27.Create TLS secret webhook-server-tls for secure webhook communication in webhook-demo namespace.
We have already created below cert and key for webhook server which should be used to create secret.
Certificate : /root/keys/webhook-server-tls.crt
Key : /root/keys/webhook-server-tls.key
kubectl -n webhook-demo create secret tls webhook-server-tls --cert "/root/keys/webhook-server-tls.crt" --key "/root/keys/webhook-server-tls.key"
secret/webhook-server-tls created
🟡 28. Kubernetes 클러스터의 각 노드(node)의 리소스 사용량
kubectl top node
🟡 29. Kubernetes 클러스터의 각 노드(pod)의 리소스 사용량
kubectl top pods
🟡 29. Kubernetes 클러스터의 각 파드 로그확인
kubectl logs <파드이름>
1. 롤링 업데이트 (Rolling Update)
- 기본 배포 방식 (Deployment에서 기본).
- 기존 파드를 조금씩 종료하면서, 새 버전 파드를 조금씩 배포.
- 다운타임 거의 없음.
- 사용자는 옛날 버전 + 새 버전 혼합 상태를 접할 수 있음.
특징:
- 안정적, 점진적.
- 트래픽 분산되어 문제 감지 어려움.
- 되돌릴 때도 롤링 방식으로 복구.
2. 카나리 배포 (Canary Deployment)
- 새 버전을 일부 사용자에게만 먼저 배포.
- 예: 전체의 5%에게 새 버전 노출 → 문제 없으면 점진적 확대.
- 문제 생기면 빠르게 롤백 가능.
특징:
- 위험 최소화.
- 트래픽 일부로 테스트 가능.
- 세밀한 제어 필요 (Ingress, Service Mesh 등 사용).
Kubernetes에서는?
- 기본 Deployment로만은 어려움.
- 보통 두 개의 Deployment + Service 라우팅 필요.
3. 블루-그린 배포 (Blue-Green Deployment)
- Blue: 현재 운영 중인 버전.
- Green: 새로 배포한 버전.
- 배포 후, 트래픽을 한 번에 Green으로 전환.
- 문제가 생기면 다시 Blue로 빠르게 복구.
특징:
- 완전한 버전 분리.
- 전환 전까지 새 버전은 트래픽 X.
- 다운타임 거의 없음, 빠른 롤백.
Kubernetes에서는?
- 두 개의 Deployment.
- Service의 selector를 변경하여 트래픽 전환.
🟡 30 현재 띄워져있는 deploy 수정 (이미지 변경하면 트리거에 의해 자동 롤링 업데이트)
kubectl edit deploy <deploy 이름>
🟡 31 alias로 쉽게 명령어
bash: ~/.bashrc 또는 ~/.bash_profile
zsh: ~/.zshrc
alias crictl='crictl'
alias k='kubectl'
source ~/.bashrc # bash인 경우
source ~/.zshrc # zsh인 경우
🟡 32. 롤링업데이트 전략
RollingUpdateStrategy: 25% max unavailable, 25% max surge
1. maxUnavailable: 25%
업데이트 중에 동시에 다운될 수 있는 파드의 최대 비율.
전체 파드의 25%까지 비어 있어도 괜찮다는 뜻.
즉, 서비스 중지 없이 최대 25%까지는 파드가 비어도 계속 서비스 가능해야 한다는 의미.
2. maxSurge: 25%
업데이트 중에 최대 몇 개의 새 파드를 추가로 만들 수 있는지를 지정.
전체 파드 수의 25%까지 추가 생성 가능.
즉, 기존 파드 + 새 파드 = 최대 125%까지 일시적으로 증가 가능.
1. 먼저 새 파드 1개 만듦 → 총 5개 (기존 4 + 새 1)
2. 기존 파드 1개 죽임 → 총 4개 유지
3. 또 새 파드 1개 만듦 → 또 기존 1개 죽임 … 반복
4. 모두 새 버전으로 교체될 때까지 반복.
🟡 33. command 명령어 yaml 에 삽입
apiVersion: v1
kind: Pod
metadata:
name: ubuntu-sleeper-2
spec:
containers:
- name: ubuntu
image: ubuntu
command: ["sleep"]
args: ["5000"]apiVersion: v1
kind: Pod
metadata:
name: ubuntu-sleeper-3
spec:
containers:
- name: ubuntu
image: ubuntu
command:
- "sleep"
- "1200"
🟡 34. 실제로 도커파일을 사용하는 yaml파일의 command는 진입점을 무시하고 yaml의 커맨드 명령어만 실행된다.
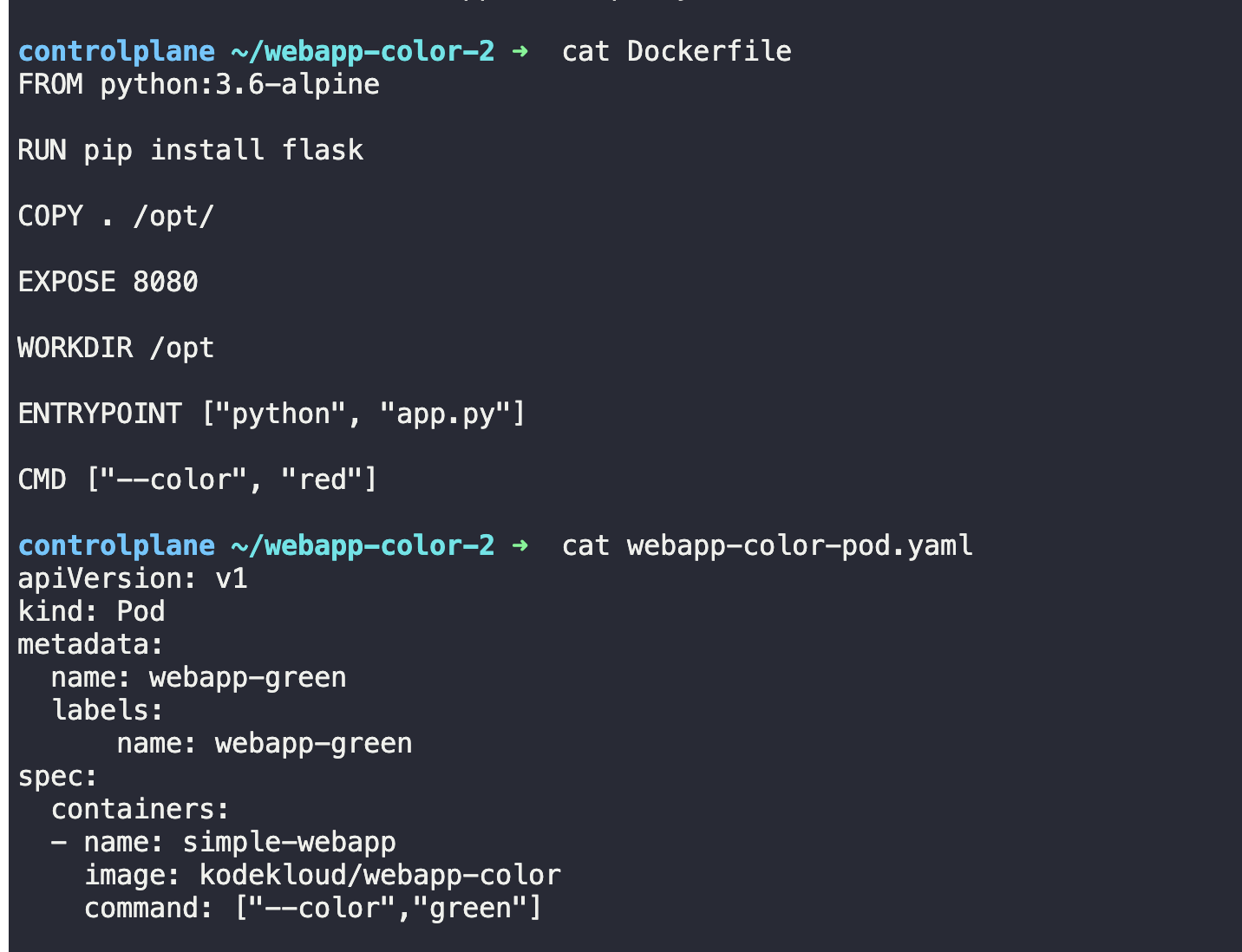
🟡 35. 커맨드명령어와 매개변수값 지정한 pod 생성

🟡 36. MultiContainer 생성
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: yellow
name: yellow
spec:
containers:
- image: busybox
name: lemon
command: ["sleep","1000"]
- image: redis
name: gold
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
🟡 37. 컨테이너 내부 bash 쉘로 들어가서 로그확인
kubectl exec app -- cat /log/app.log
🟡 38. 2개의 컨테이너가 공유하는 path 불륨마운트로 설정하기
Name: app
Container Name: sidecar
Container Image: kodekloud/filebeat-configured
Volume Mount: log-volume
Mount Path: /var/log/event-simulator/
Existing Container Name: app
Existing Container Image: kodekloud/event-simulator
🟡 39. initContainer sleep 600 = 10분
Command:
sh
-c
sleep 600
State: Running
Started: Tue, 29 Apr 2025 12:34:52 +0000
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-lgbf4 (ro)
warm-up-2:
Container ID:
Image: busybox:1.28
Image ID:
Port: <none>
Host Port: <none>
Command:
sh
-c
sleep 1200🟡 40. InitContainer 기존파드에 update

🟡 41. 멀티 컨테이너 환경에서 해당 파드안에있는 컨테이너 로그확인 후 에러확인
k logs orange -c init-myservice
🟡 42. Node node01 Unschedulable Pods evicted from node01
k drain node01 --ignore-daemonsets
node/node01 already cordoned
Warning: ignoring DaemonSet-managed Pods: kube-flannel/kube-flannel-ds-5zhgj, kube-system/kube-proxy-s5g9x
evicting pod default/blue-69968556cc-mqvb7
evicting pod default/blue-69968556cc-4mkjq
evicting pod default/blue-69968556cc-9fhkd
pod/blue-69968556cc-mqvb7 evicted
pod/blue-69968556cc-9fhkd evicted
pod/blue-69968556cc-4mkjq evicted
node/node01 drained
🟡 43. 노드의 이러한 SchedulingDisabled 상태를 제거하여 노드에 Pod이 정상적으로 스케쥴링 될 수 있도록 복구하는 명령어
k uncordon node01
🟡 43. node의 파드 강제 drained
pod will be lostt forever
🟡 44. how many nodes can host workloads in this cluster
inspect the application and taints set on the nodes

kubectl kubelet kubeadm
| 용도 | 클러스터 제어 | 노드에서 Pod 실행 및 관리 | 클러스터 설치 및 초기화 |
| 실행 위치 | 사용자 PC 또는 관리 노드 | 각 Kubernetes 노드 | 마스터/워커 초기 설치 대상 노드 |
| 사용 대상 | 개발자, 운영자 | 시스템 (노드 자체에서 실행) | 클러스터 설치자 (운영자) |
🟡 45. kubeadm 업그레이드
kubeadm upgrade plan🟡 46. controlplane upgrade
sudo apt-mark unhold kubeadm && \
sudo apt-get update && sudo apt-get install -y kubeadm='1.32.0' && \
sudo apt-mark hold kubeadm
🟡 46. cordon 과 uncordon 차이
| 파드 스케줄링 | ❌ 불가능하게 함 | ✅ 가능하게 함 |
| 실행 중 파드 | 영향 없음 | 영향 없음 |
| 사용 목적 | 유지보수, 노드 관리 등 | 정상 운영 복구용 |
🟡 47. Upgrade the worker node to the exact version v1.32.0
sudo apt-get update
sudo apt-get install -y kubeadm kubelet kubectl
sudo apt-mark hold kubeadm kubelet kubectl
🟡 47. kubeconfig 클러스터 갯수 확인
kubectl config view.
🟡 48. 클러스터 변경
kubectl config use-context cluster1
🟡 48. 다른 클러스터로 SSH접속
ssh cluster1-controlplane
컴포넌트 역할 설명
| etcd | 클러스터의 실제 상태 데이터 저장소 |
| kube-apiserver | etcd에 데이터를 읽고 쓰는 유일한 컴포넌트. 모든 요청은 여기로 통함 |
| kubectl 등 클라이언트 | API Server에 요청 → API Server가 etcd와 통신 |
🟡 49. 현재 호스트 IP확인
hostname -I
192.168.20.183
🟡 49. ETCD접속 및 확인
ssh etcd-server
ps -ef | grep -i etcd
🟡 50. ETCD 몇대의 클러스터가 들어가있는지 확인
ps -ef | grep -i etcd
etcd 774 1 0 04:13 ? 00:01:24 /usr/local/bin/etcd --name etcd-server --data-dir=/var/lib/etcd-data --cert-file=/etc/etcd/pki/etcd.pem --key-file=/etc/etcd/pki/etcd-key.pem --peer-cert-file=/etc/etcd/pki/etcd.pem --peer-key-file=/etc/etcd/pki/etcd-key.pem --trusted-ca-file=/etc/etcd/pki/ca.pem --peer-trusted-ca-file=/etc/etcd/pki/ca.pem --peer-client-cert-auth --client-cert-auth --initial-advertise-peer-urls https://192.168.114.198:2380 --listen-peer-urls https://192.168.114.198:2380 --advertise-client-urls https://192.168.114.198:2379 --listen-client-urls https://192.168.114.198:2379,https://127.0.0.1:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster etcd-server=https://192.168.114.198:2380 --initial-cluster-state new--initial-cluster etcd-server=https://192.168.114.198:2380
🟡 51. etcd 스냅샷 저장
여기서 나온 정보를 바탕으로 snatshot 설정
해당 control plane 접속하여 etcd정보 decribe
Command:
etcd
--advertise-client-urls=https://192.168.187.156:2379
--cert-file=/etc/kubernetes/pki/etcd/server.crt
--client-cert-auth=true
--data-dir=/var/lib/etcd
--experimental-initial-corrupt-check=true
--experimental-watch-progress-notify-interval=5s
--initial-advertise-peer-urls=https://192.168.187.156:2380
--initial-cluster=cluster1-controlplane=https://192.168.187.156:2380
--key-file=/etc/kubernetes/pki/etcd/server.key
--listen-client-urls=https://127.0.0.1:2379,https://192.168.187.156:2379
--listen-metrics-urls=http://127.0.0.1:2381
--listen-peer-urls=https://192.168.187.156:2380
--name=cluster1-controlplane
--peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
--peer-client-cert-auth=true
--peer-key-file=/etc/kubernetes/pki/etcd/peer.key
--peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
--snapshot-count=10000
--trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
ETCDCTL_API=3 etcdctl \
--endpoints=https://192.33.162.8:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save /opt/cluster1.dbscp cluster1-controlplane:/opt/cluster1.db /opt
유데미 148 backup and restore 15번 다시 풀어보기 /opt/cluster2.db
🟡 52. scp로 로컬에 있는 스냅샷 etcd에 올려서 restore
sudo ETCDCTL_API=3 etcdctl snapshot restore /opt/cluster2.db \
--data-dir=/var/lib/etcd-data-new이후
vi /etc/systemd/system/etcd.service
data-dir경로 수정이후
systemctl daemon-reload
systemctl restart etcd
systemctl status etcd
🟡 53. static pod, etcd 서버가 위치하는 디렉토리 경로
cat /etc/kubernetes/manifests/etcd.yaml
🟡 54. CN configured on the kube api server certificate
openssl x509 -in /etc/kubernetes/pki/etcd/ca.crt -text -noout
🟡 55. 쿠버네티스 CPU별 오름차순
| kubectl top pod 또는 kubectl top po | 현재 클러스터에서 파드들의 리소스(CPU, 메모리) 사용량을 보여줌 |
| -n <namespace> | 어떤 네임스페이스에서 실행할지를 지정 |
| -l <key>=<value> | 라벨 셀렉터 (해당 라벨을 가진 파드만 필터링) |
| --sort-by=cpu | CPU 사용량 기준으로 정렬하여 보여줌 |
// top 명령어와 --sort-by 옵션 활용
k top po -n <name-space> -l <key>:<value> --sort-by=cpu
echo "<pod-name>" > /문제에서/주어진/경로/
🟡 56. NetworkPolicy를 생성하여 특정 namspace의 Pod의 요청만 정해진 포트를 통해 들어올 수 있도록 하라.(ingress)
# 공식문서에서 가져온 예시
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy -> 문제에서 주어진대로 수정
namespace: default -> 문제에서 주어진대로 수정
spec:
podSelector:
matchLabels:
role: db -> 문제에서 주어진대로 수정
policyTypes:
- Ingress
- Egress
ingress:
- from:
- namespaceSelector:
matchLabels:
project: myproject -> 문제에서 주어진대로 수정
- podSelector:
matchLabels:
role: frontend -> 문제에서 주어진대로 수정
ports:
- protocol: TCP
port: 6379 -> 문제에서 주어진대로 수정
ㅁ 시험 시 팁
ㅇ 명령어 타이프 시간을 줄이기 위해 줄임 명령어를 사용함
# (기본설정) kubectl을 k로 줄여주어서 타자 시간을 멀어줌.
alias k=kubectl # 시험환경에 이미 설정됨.
# (설정필요) sample yaml 얻거나 yaml 문법 정상 테스트 시 자주 사용
export do="--dry-run=client -o yaml" # k create deploy nginx --image=nginx $do
# (설정필요) pod 삭제 시 즉시 수행됨
export now="--force --grace-period 0" # k delete pod x $now ㅇ pod가 삭제될 때에 graceful shutdown 정책이 기본 정해져, container의 프로세스 종료를 위한 지연이 발생한다.
ㅇ kill -15면 어플리케이션 종료 명령어이듯, 위의 force delete는 kill -9 즉시 종료에 해당하는 방법이다.
ㅁ Cluster 관련
ㅇ Cluster Upgrade (Controlplane Node만 진행)
ㄴ [CKA] Udemy 실습문제풀이 - Cluster Maintenance
# master upgrade
1. master node drain
2. master node의 kubeadm upgrade
3. master node의 kubelet, kubectl upgrade 및 daemon restart
4. master node의 uncordon
# work upgrade
1. work node drain
2. work node ssh 접속
3. work node의 kubeadm upgrade
3. work node의 kubelet, kubectl upgrade 및 daemon restart
4. work node의 uncordonㅇ ETCD snapshot save & restore
ㄴ 빠지지 않고 나오는 고득점 문제.
ㄴ 공식문서에서 명령어 복사 후 문제에 주어진 옵션 값 복붙으로 명령문 완성 후 실행
ㄴ [CKA] 기출문제 - ETCD Backup and Restore
ㅁ 트러블 슈팅 관련
ㅇ 특정 Node가 NotReady 상태인데 Ready가 되도록 TroubleShooting(고배점 문제)
# 문제 노드 확인
$ k get no
# ssh 접속
ssh wk8s-node-0
# 루트 권한 설정
$ sudo -i
# kubelet 서비스 상태 확인
$ systemctl status kubelet
... inactive 상태 확인
# 재기동
$ systemctl restart kubelet
# 상태확인
$ systemctl status kubelet
... active 상태 확인
ㅁ Resource 관련
ㅇ PVC 생성 후 Pod와 PVC 연동 (PV는 이미 존재), PVC 용량 수정
ㄴ 스토리지 클래스의 allowVolumeExpansion 필드가 true로 설정된 경우에만 PVC를 확장할 수 있다.
ㄴ 공식문서:
- 스토리지로 퍼시스턴트볼륨(PersistentVolume)을 사용하도록 파드 설정하기
- 퍼시스턴트 볼륨 클레임 확장
# 문제에서 storageclasses를 지정해 주지 않으면 기본을 사용한다.
$ k get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
standard (default) k8s.io/minikube-hostpath Delete Immediate true 17d
# 확장가능 확인, AllowVolumeExpansion: True
$ k describe sc standard
Name: standard
IsDefaultClass: Yes
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"storage.k8s.io/v1","kind":"StorageClass","metadata":{"annotations":{"storageclass.kubernetes.io/is-default-class":"true"},"labels":{"addonmanager.kubernetes.io/mode":"EnsureExists"},"name":"standard"},"provisioner":"k8s.io/minikube-hostpath"}
,storageclass.kubernetes.io/is-default-class=true
Provisioner: k8s.io/minikube-hostpath
Parameters: <none>
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: Immediate
Events: <none>
# 기본 storageClass 수정
# allowVolumeExpansion: true
$ k edit sc standard
..............
allowVolumeExpansion: true <=== 추가
# PV 생성, 공식문서 참조(pods/storage/pv-volume.yaml)
apiVersion: v1
kind: PersistentVolume
metadata:
name: task-pv-volume
labels:
type: local
spec:
storageClassName: standard <=== 기본으로 수정
capacity:
storage: 10Mi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
$ k apply -f pv.yaml
persistentvolume/task-pv-volume created
# PVC 생성, 공식문서 참조(pods/storage/pv-claim.yaml)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: standard <=== 기본으로 수정
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Mi <== 수정함
$ k apply -f pvc.yaml
persistentvolumeclaim/task-pv-claim created
# 확인
$ k get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/task-pv-volume 10Mi RWO Retain Bound default/task-pv-claim manual 30s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/task-pv-claim Bound task-pv-volume 10Mi RWO manual 26s
# POD 생성, 공식문서 참조(pods/storage/pv-pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
$ k apply -f pv-pod.yaml
pod/task-pv-pod created
# pvc 10Mi -> 90Mi 용량 변경
$ k edit pvc task-pv-claim
...........
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 90Mi <== 변경
storageClassName: manual
volumeMode: Filesystem
volumeName: task-pv-volume
...........
persistentvolumeclaim/task-pv-claim edited
# 변경 이벤트 확인
#
$ k describe pvc task-pv-claim
..............
Warning ExternalExpanding 3m11s volume_expand waiting for an external controller to expand this PVC
ㅇ sidecar multi containers로 sidecar의 log 확인하기
ㄴ 기존 container에 volume emptyDir 설정하여 /var/log를 공유하여 sidecar로 로그 확인
ㄴ 공식문서: 로깅 에이전트가 있는 사이드카 컨테이너
ㄴ 동영상: [따배씨] 05. Side-car Container Pod 실행하기
# 테스트를 위한 사전 pod.yaml 작성 및 실행
apiVersion: v1
kind: Pod
metadata:
name: eshop-cart-app
spec:
containers:
- image: busybox
name: cart-app
command:
- /bin/sh
- -c
- 'i=1;while :;do echo -e "$i: Price: $((RANDOM % 10000 + 1))" >> /var/log/cart-app.log;
i=$((i+1)); sleep 2; done'
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- emptyDir: {}
name: varlog
# 로그확인 시 로그가 보이지 않는다.
$ k logs eshop-cart-app
# 공식문서 > 로깅 에이전트와 함께 사이드카 컨테이너 사용
> admin/logging/two-files-counter-pod-streaming-sidecar.yaml에서 복사
.......
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
.......
# 시험환경에서
# 기존 콘테이너에서 yaml 복사, 문제번호+log.yaml
$ k get po eshop-cart-app -o yaml > 9-log.yaml
apiVersion: v1
kind: Pod
metadata:
name: eshop-cart-app
spec:
containers:
- image: busybox
name: cart-app
command:
- /bin/sh
- -c
- 'i=1;while :;do echo -e "$i: Price: $((RANDOM % 10000 + 1))" >> /var/log/cart-app.log;
i=$((i+1)); sleep 2; done'
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/cart-app.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- emptyDir: {}
name: varlog
# yaml 검증
$ k apply -f 9-log.yaml --dry-run=server
The Pod "eshop-cart-app" is invalid: spec.containers: Forbidden: pod updates may not add or remove containers
... 문법오류가 발생하지 않으면 pod container의 추가 수정은 불가 경고가 뜬다.
# 적용을 위한 기존 pod 제거
# delete 시 시간이 소요되어 즉시 삭제 옵션 추가 --force --grace-period 0
$ k delete po eshop-cart-app --force --grace-period 0
# 적용
$ k apply -f 9-log.yaml
# 로그 확인
$ k logs eshop-cart-app count-log-1
1: Price: 9575
2: Price: 4341
3: Price: 406
4: Price: 8355
5: Price: 6885
6: Price: 4549
ㅇ Pod에 nodeSelector (disktype=ssd) 추가
# node-selector.yaml 생성
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
nodeSelector:
disktype: ssd
# apply
$ k apply -f node-selector.yaml
# 확인
k get po nginx -o wide
ㅇ 이미지 nginx 1.16으로 Deployment 생성 후 이미지를 nginx 1.17로 업그레이드 하기
# nginx 1.16 생성
$ k create deploy deploy01 --image nginx:1.16
# nginx 1.17 변경
$ k set image deployment/deploy01 nginx=nginx:1.17
ㅁ 네트워크
ㅇ Pod(port 80)생성하고 NodePort타입 Service 생성
# pod 생성
$ k run nginx-resolver --image nginx
# pod expose
$ k expose pod nginx-resolver -name nginx-resolver-service\
--port 80 --target-port 80 --type NodePort
# 확인
$ k get svc nginx-resolver-service -o yaml
ㅇ Ingress를 생성해서 이미 생성 되어 있는 서비스와 연결하고 확인
ㄴ 테스트를 위해 외부 IP 주소를 노출하여 클러스터의 애플리케이션에 접속하기 기준으로 deployment와 service-LoadBalancer을 생성하였다.
# deployment 생성 - containerPort: 8080
$ k apply -f https://k8s.io/examples/service/load-balancer-example.yaml
# service 생성
$ k expose deployment hello-world --type=LoadBalancer --name=my-service
# service 확인
$ k get svc my-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service LoadBalancer 10.96.209.198 10.96.209.198 8080:31426/TCP 33m
ㄴ 문제에서 /hi로 요청이 오면 기존 서비스로 연결

ㄴ 인그레스 리소스에서 service/networking/minimal-ingress.yaml 샘플 복사
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx-example <== 삭제
rules:
- http:
paths:
- path: /hi <== 수정
pathType: Prefix
backend:
service:
name: my-service <== 수정
port:
number: 80
# 적용
$ k apply -f minimal-ingress.yaml
ingress.networking.k8s.io/minimal-ingress created
# 확인
$ k describe ingress minimal-ingress
Name: minimal-ingress
Labels: <none>
Namespace: default
Address:
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
*
/hi my-service:80 (10.244.0.154:8080,10.244.0.155:8080,10.244.1.17:8080 + 2 more...)
ㅇ Networkpolicy를 생성해서 특정 namespace의 Pod만 특정 경로로 연결
ㄴ 참고 동영상: [따배씨] 30.Network Policy
ㄴ 공식문서 검색: The NetworkPolicy resource
# 공식문서에서 예문 복사
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy <== 변경
namespace: default <== 변경
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
project: myproject <== 변경
- podSelector:
matchLabels:
role: frontend <== 변경
ports:
- protocol: TCP
port: 80
# 적용
$ k apply -f ploicy.yaml
# 확인
$ k describe networkpolicy -n default test-network-policy
...PodSelector, To Port, From NamespaceSelector 체크
ㅁ 권한 관련
ㅇ ServiceAccount 생성, Role 생성, Role Binding 생성 후 확인
# serviceaccount 생성
$ k create serviceaccount john $do > sa.yaml
# apply
$ k apply -f sa.yaml
# role 생성
$ k -n development create role developer --resource=pods --verb=create
$ k -n development create rolebinding developer-role-binding \
--role=developer --user=john
ㅁ 스케줄 관련
ㅇ 특정 Node를 drain하여 해당 노드는 SchedulingDisabled상태로 변경하고 Pod를 다른 Node로 옮기기
# 특정노드 이름 조회
$ k get no --show-labels | grep k8s-node-0
# # node drain
# DaemonSet에서 관리하는 포드가 있는 경우
# 노드를 성공적으로 비우려면 --ignore-daemonsetswith를 지정해야한다.
$ k drain --ignore-daemonsets k8s-node-0
# node 상태 확인
$ k get no -o wide
# pod의 위치확인
$ k get po -o wide
ㅇ 특정 Deployment에 대해 replicas 수정
ㄴ 공식문서: 디플로이먼트 스케일링
$ k scale deployment/nginx-deployment --replicas=10
ㅁ 필터를 통한 데이터 추출
ㅇ Pod에서 log grep해서 파일로 추출
# ErrorMessage 로그필터
$ k logs podName | grep ErrorMessage > 답안경로
ㅇ Taint가 없는 Node의 개수를 파일로 저장
# 노드 확인
$ k get no => 노드 갯수 3개 확인
# k describe no | grep -i taint
Taints: <none> <== 없는 것은 none으로 확인
# 답안작성
echo '2' > 답안파일 경로
ㅇ Node의 상태가 ready 개수를 파일로 저장
ㄴ 이런 간단한 문제들은 kubectl Quick Reference에서 검색을 해봅니다.
ㄴ ready로 웹 검색을 하면 다음과 같은 방법 확인
# Check which nodes are ready
JSONPATH='{range .items[*]}{@.metadata.name}:{range @.status.conditions[*]}{@.type}={@.status};{end}{end}' \
&& kubectl get nodes -o jsonpath="$JSONPATH" | grep "Ready=True"
# Check which nodes are ready with custom-columns
kubectl get node -o custom-columns='NODE_NAME:.metadata.name,STATUS:.status.conditions[?(@.type=="Ready")].status'ㄴ 응용하여 완성
$ k get node -o custom-columns='NODE_NAME:.metadata.name,STATUS:.status.conditions[?(@.type=="Ready")].status' --no-headers| wc -l > 파일명
ㅇ 사용률이 가장 높은 Pod를 특정 label로만 조회해서 파일로 저장
# 특정 namespace에 control-plane(샘플)라벨로 필터하여 cpu로 정렬
k top po -n kube-system -l tier=control-plane --sort-by=cpu
# 답안작성
$ echo '노드이름' > 답변 파일 위치
기출문제
- [Storage] 1. pv hostpath 볼륨 마운트
- [Workloads & Scheduling] 2. 기존 팟 수정해서 볼륨에 로그 저장하는 사이드카 컨테이너 붙이기 (커맨드 추가)
- [Cluster Architecture] 3. etcd 복구
- [Troubleshooting] 4. 워커노드 트러블슈팅(kubelet)
- [Troubleshooting] 5. pod 특정 레이블 중 top cpu 파드 이름 저장
- [Troubleshooting] 6.taint된 노드 개수
- [Services & Networking] 7. ingress 재작 후 curl 테스트
- [Storage]8. 멀티컨테이너 파드 만들기
- [Services & Networking]9. 조건에따라 networkpolicy 만들기 (특정 네임스페이스, 포트, 파드로 가는 트래픽 허용)
- [Cluster Architecture] 10. 마스터 노드 업그레이드
- [Services & Networking] 11. 디플로이먼트 expose 하는 nodeport 타입 서비스 만들기
- [Workloads & Scheduling] 12. pod disktype
- [workloads & Scheduling] 13.디플로이먼트 파드 스케일링 (presentation이라는 디플로이먼트를 5개로 늘리기)
- [Cluster Architecture] 14. svc 생성 후 클러스터롤 , 바인딩하기
- [Workloads & Scheduling] 15. 워커 노드 비우기
- [Workloads & Scheduling] 16. pod error log 확인 후 저장
- [Storage] 17. pvc만들고 만든 뒤에 capacity 늘리기 (record)
- [Workloads & Scheduling] 18. deployment (kubectl set image)
- [Services & Networking] 19. pod를 이용한 name service 구성
- [Workloads & Scheduling] 20. static pod 생성
유데미 1번 기출문제
apiVersion: v1
kind: Pod
metadata:
name: mc-pod
namespace: mc-namepsace
spec:
containers:
- name: mc-pod-1
image: nginx:1-alpine
env:
- name: MY_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumeMounts:
- name: varlog
mountPath: /var/log/shared
- name: mc-pod-2
image: busybox:1
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/shared/date.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log/shared
- name: mc-pod-3
image: busybox:1
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/shared/date.log']
volumeMounts:
- name: varlog
mountPath: /var/log/shared
volumes:
- name: varlog
emptyDir: {}
2번문제
ssh로 bob로 접속하여
데비안 패키지 install
sudo dpkg -i cri-docker_0.3.16.3-0.debian.deb
systemctl start cri-docker
systemctl enable cri-docker
활성화되어있는지 확인
systemctl is-active cri-docker
systemctl is-enable cri-docker
3번문제
kubectl get crds | grep verticalpodautoscaler | awk '{print $1}' > ~/vpa-crds.txt
crds Kubernetes Custom Resource Definitions
확인
cat /root/vpa-crds.txt
4번문제
kubectl expose pod messaging --name=messaging-service --port=6379 --target-port=6379 --type=ClusterIP
5번문제
kubectl create deploy hr-web-app --image=kodekloud/webapp-color -r=2
6번문제
❌ Wrong image kubectl set image deployment/orange orange-container=<correct-image>
❌ Port not exposed kubectl expose deployment orange --port=80 --target-port=8080
❌ CrashLoop in logs Edit config or command: kubectl edit deployment orange
❌ Not scheduled (No node) Check node resources, taints
Successfully pulled image "busybox" in 159ms (159ms including waiting). Image size: 2156519 bytes.
Warning BackOff 62s (x26 over 6m37s) kubelet Back-off restarting failed container init-myservice in pod orange_default(0e7c0570-9f8c-4baa-85e2-183e95988783)
kubectl logs orange -c init-myservice
로그보고 수정 후
k replace --force -f /tmp/kubectl-edit-1127017126.yaml
k get pod로 확인
7번문제
apiVersion: v1
kind: Service
metadata:
name: hr-web-app-service
spec:
type: NodePort
selector:
app: hr-web-app
ports:
- port: 8080 # 클러스터 내부에서 접근할 포트
targetPort: 8080 # 실제 Pod 컨테이너에서 열려 있는 포트
nodePort: 30082 # 클러스터 외부(Node IP)에서 접근할 포트
protocol: TCP
8번문제
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-analytics
spec:
capacity:
storage: 100Mi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /pv/data-analytics
9번문제
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: webapp-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kkapp-deploy
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
behavior:
scaleDown:
stabilizationWindowSeconds: 300
10번문제
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: analytics-vpa
namespace: default
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: analytics-deployment
updatePolicy:
updateMode: "Auto"
11번문제
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: example-gateway
spec:
gatewayClassName: example-class
listeners:
- name: http
protocol: HTTP
port: 80
12번문제
One co-worker deployed an nginx helm chart kk-mock1 in the kk-ns namespace on the cluster. A new update is pushed to the helm chart, and the team wants you to update the helm repository to fetch the new changes.
After updating the helm chart, upgrade the helm chart version to 18.1.15.
helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "kk-mock1" chart repository
Update Complete. ⎈Happy Helming!⎈
controlplane ~ ➜ helm get all kk-mock1 -n kk-ns | grep CHART
CHART: nginx
CHART NAME: nginx
CHART VERSION: 18.1.0
helm search repo nginx --versions
helm upgrade kk-mock1 kk-mock1/nginx --version 18.1.15 -n kk-ns
helm list -n kk-ns
demo2번 exam
1. Take a backup of the etcd cluster and save it to /opt/etcd-backup.db.
# ETCD 백업문제, 백업 말고 Restore 쪽도 공부 해야한다.
$ cd /etc/kubernetes/manifests
$ cat etcd.yaml
# ca.crt / server.crt / server.key 경로를 확이하고 다음 명령어를 실행
$ ETCDCTL_API=3 etcdctl --cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> snapshot save /opt/etcd-backup.db
2. Create a Pod called redis-storage with image: redis:alpine with a Volume of type emptyDir that lasts for the life of the Pod. Specs on the right.
- Pod named 'redis-storage' created
- Pod 'redis-storage' uses Volume type of emptyDir
- Pod 'redis-storage' uses volumeMount with mountPath = /data/redis
$ kubectl run redis-storage --image=redis:alpine --dry-run=client -o yaml > redis-storage.yaml
$ vi redis-storage.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: redis-storage
name: redis-storage
spec:
containers:
- image: redis:alpine
name: redis-storage
resources: {}
volumeMounts:
- mountPath: /data/redis
name: redis-storage
volumes:
- name: redis-storage
emptyDir: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
$ kubectl apply -f redis-storage.yaml
3. Create a new pod called super-user-pod with image busybox:1.28. Allow the pod to be able to set system_time. sleep 4800.
- Pod: super-user-pod
- Container Image: busybox:1.28
- SYS_TIME capabilities for the conatiner?
$ kubectl run super-user-pod --image=busybox:1.28 --dry-run=client -o yaml > super-user-pod.yaml
$ vi super-user-pod.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: super-user-pod
name: super-user-pod
spec:
containers:
- image: busybox:1.28
name: super-user-pod
resources: {}
command: ["sleep", "4800"]
securityContext:
capabilities:
add: ["SYS_TIME"]
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
$ kubectl apply -f super-user-pod.yaml
4. A pod definition file is created at /root/CKA/use-pv.yaml. Make use of this manifest file and mount the persistent volume called pv-1. Ensure the pod is running and the PV is bound. mountPath: /data persistentVolumeClaim Name: my-pvc
mountPath: /data
persistentVolumeClaim Name: my-pvc
- persistentVolume Claim configured correctly
- pod using the correct mountPath
- pod using the persistent volume claim
$ cd /root/CKA
$ cat use-pv.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: use-pv
name: use-pv
spec:
containers:
- image: nginx
name: use-pv
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
$ vi pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Mi
$ kubectl apply -f pvc.yaml
$ vi use-pv.yaml
apiVersion: v1
kind: Pod
metadata:
name: use-pv
spec:
containers:
- image: nginx
name: use-pv
volumeMounts:
- mountPath: "/data"
name: my-pvc
volumes:
- name: my-pvc
persistentVolumeClaim:
claimName: my-pvc
$ kubectl apply -f use-pv.yaml
5. Create a new deployment called nginx-deploy, with image nginx:1.16 and 1 replica. Record the version. Next upgrade the deployment to version 1.17 using rolling update. Make sure that the version upgrade is recorded in the resource annotation.
- Deployment : nginx-deploy. Image: nginx:1.16
- Image: nginx:1.16
- Task: Upgrade the version of the deployment to 1:17
- Task: Record the changes for the image upgrade
$ kubectl run nginx-deploy --image=nginx:1.16 replicas=1 --record --dry-run=client -o yaml > nginx-deploy.yaml
$ vi nginx-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16
$ kubectl apply -f nginx-deploy.yaml
$ kubectl set image deployment/nginx-deploy nginx=nginx:1.17 --record
$ kubectl rollout history deployment nginx-deploy
6. Create a new user called john. Grant him access to the cluster. John should have permission to create, list, get, update and delete pods in the development namespace. The private key exists in the location: /root/CKA/john.key and csr at /root/CKA/john.csr
Important Note: As of kubernetes 1.19, the CertificateSigningRequest object expects a signerName.
Please refer the documentation to see an example. The documentation tab is available at the top right of terminal.
- CSR: john-developer Status:Approved
- Role Name: developer, namespace: development, Resource: Pods
- Access: User 'john' has appropriate permissions
$ vi john.yaml
7. Create an nginx pod called nginx-resolver using image nginx, expose it internally with a service called nginx-resolver-service. Test that you are able to look up the service and pod names from within the cluster. Use the image: busybox:1.28 for dns lookup. Record results in /root/CKA/nginx.svc and /root/CKA/nginx.pod
- Pod: nginx-resolver created
- Service DNS Resolution recorded correctly
- Pod DNS resolution recorded correctly
$ kubectl run nginx-resolver --image=nginx
$ kubectl expose pod nginx-resolver --name=nginx-resolver-service --port=80 --target-port=80 --type=ClusterIP
# 테스트
$ kubectl run test-nslookup --image=busybox:1.28 --rm -it -- nslookup nginx-resolver-service > /root/nginx.svc
# IP 복사 후
$ kubectl get pod nginx-resolver -o wide
$ kubectl run test-nslookup --image=busybox:1.28 --rm -it -- nslookup 10-32-0-5.default.pod > /root/nginx.pod
# 클러스터 내의 모든 서비스(DNS 서버 자신도 포함하여)에는 DNS 네임이 할당된다. 기본적으로 클라이언트 파드의 DNS 검색 리스트는 파드 자체의 네임스페이스와 클러스터의 기본 도메인을 포함한다.
8. Create a static pod on node01 called nginx-critical with image nginx. Create this pod on node01 and make sure that it is recreated/restarted automatically in case of a failure.
Use /etc/kubernetes/manifests as the Static Pod path for example.
- static pod configured under /etc/kubernetes/manifests ?
- Pod nginx-critical-node01 is up and running
$ kubectl get nodes
$ ssh node01
# kubelet config 파일 경로를 확인 하자.
$ systemctl status kubelet
# config 파일에서 statisPodPath를 확인.
$ cat /var/lib/kubelet/config.yaml | grep staticPodPath
$ cd /etc/kubernetes
$ mkdir manifests
# 마스터 노드로 복귀
$ logout
$ kubectl run nginx-critical --image=nginx --dry-run=client -o yaml > nginx-critical.yaml
$ cat >> nginx-critical.yaml
# 출력 되는 내용을 복사한다.
$ ssh node01
$ cd /etc/kubernetes/manifests
$ vi nginx-ciritical.yaml
# 붙여넣기 후 저장
# kubectl apply는 staitcPod 디렉토리에 yaml을 넣었기 때문에 안해도 된다.
$ logout
$ kubectl get pods
# 확인
demo3
1번문제
https://kubernetes.io/docs/setup/production-environment/container-runtimes/#containerd-systemd
# sysctl params required by setup, params persist across reboots
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# Apply sysctl params without reboot
sudo sysctl --system
2번문제
# serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: pvviewer
namespace: default
# clusterrole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: pvviewer-role
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list"]
# clusterrolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: pvviewer-role-binding
subjects:
- kind: ServiceAccount
name: pvviewer
namespace: default
roleRef:
kind: ClusterRole
name: pvviewer-role
apiGroup: rbac.authorization.k8s.io
# pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pvviewer
namespace: default
spec:
serviceAccountName: pvviewer
containers:
- name: redis
image: redis
kubectl apply -f serviceaccount.yaml
kubectl apply -f clusterrole.yaml
kubectl apply -f clusterrolebinding.yaml
kubectl apply -f pod.yaml
3번문제
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rancher-sc
annotations:
storageclass.kubernetes.io/is-default-class: "false"
provisioner: rancher.io/local-path
reclaimPolicy: Retain # default value is Delete
allowVolumeExpansion: true
mountOptions:
- discard # this might enable UNMAP / TRIM at the block storage layer
volumeBindingMode: WaitForFirstConsumer
parameters:
guaranteedReadWriteLatency: "true" # provider-specific
4번문제
# configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
namespace: cm-namespace
data:
ENV: production
LOG_LEVEL: info
kubectl apply -f configmap.yaml
# patch-deployment.yaml (기존 cm-webapp에 ConfigMap 환경변수 연결)
apiVersion: apps/v1
kind: Deployment
metadata:
name: cm-webapp
namespace: cm-namespace
spec:
template:
spec:
containers:
- name: <your-container-name>
envFrom:
- configMapRef:
name: app-config
kubectl edit deployment cm-webapp -n cm-namespace
kubectl get configmap app-config -n cm-namespace -o yaml
5번문제
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: 50000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
apiVersion: v1
kind: Pod
metadata:
name: lp-pod
namespace: low-priority
spec:
priorityClassName: low-priority
containers:
- name: ...
image: ...
edit으로할때
priority: 0 # ❌ 직접 지정 금지
preemptionPolicy: ... # ❌ 직접 지정 금지
이거 있으면삭제 후 priorityClassName지정하기
6번
kubectl get pod np-test-1 --show-labels
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ingress-to-nptest
namespace: default
spec:
podSelector:
matchLabels:
app: cmweb-app
policyTypes:
- Ingress
ingress:
- from:
- ipBlock:
cidr: 0.0.0.0/0
ports:
- protocol: TCP
port: 80
7번
taint : 노드마다 설정가능. 설정한 노드에는 pod이 스케줄되지 않음
toleration : taint를 무시할수있음
kubectl taint nodes node01 env_type=production:NoSchedule
# dev-redis.yaml
apiVersion: v1
kind: Pod
metadata:
name: dev-redis
namespace: default
spec:
containers:
- name: redis
image: redis:alpine
# prod-redis.yaml
apiVersion: v1
kind: Pod
metadata:
name: prod-redis
namespace: default
spec:
containers:
- name: redis
image: redis:alpine
tolerations:
- key: "env_type"
operator: "Equal"
value: "production"
effect: "NoSchedule"
🔹 dev-redis가 node01에 안 올라갔는지 확인
kubectl get pod dev-redis -o wide
🔹 prod-redis가 node01에 올라갔는지 확인
kubectl get pod prod-redis -o wide
8번
A PersistentVolumeClaim named app-pvc exists in the namespace storage-ns, but it is not getting bound to the available PersistentVolume named app-pv. Inspect both the PVC and PV and identify why the PVC is not being bound and fix the issue so that the PVC successfully binds to the PV. Do not modify the PV resource. Is PVC correctly bound to PV?
항목 설명
| storageClassName | 둘 다 동일하거나, 둘 다 "" (empty string) |
| accessModes | PVC의 accessModes가 PV에서 제공하는 것 중 하나와 일치 |
| resources.requests.storage | PVC의 요청 용량이 PV의 용량보다 같거나 작아야 함 |
| selector | PVC가 selector를 지정했다면, PV의 labels가 일치해야 함 |
| volumeMode | (선택적) Filesystem / Block 동일해야 함 |
| PV의 상태 | Available 상태여야 하고, 다른 PVC에 바인딩되어 있으면 안 됨 |
kubectl get pvc app-pvc -n storage-ns
kubectl get pvc app-pvc -n storage-ns -o yaml > pvc.yaml
kubectl get pv app-pv -o yaml > pv.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: app-pvc
namespace: storage-ns
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: "" # <== 이거 중요!
volumeName: app-pv # 명시적으로 PV 지정
kubectl delete pvc app-pvc -n storage-ns
kubectl apply -f pvc.yaml
9번
A kubeconfig file called super.kubeconfig has been created under /root/CKA. There is something wrong with the configuration. Troubleshoot and fix it.
Fix /root/CKA/super.kubeconfig
kubectl --kubeconfig=/root/CKA/super.kubeconfig get nodes
여기서 나온 에러를 기준으로 수정
10번
We have created a new deployment called nginx-deploy. Scale the deployment to 3 replicas. Has the number of replicas increased? Troubleshoot and fix the issue.
Does the deployment have 3 replicas?
edit해서 deploy수정한다음에
확인
11번
Create a Horizontal Pod Autoscaler (HPA) for the deployment named api-deployment located in the api namespace.
The HPA should scale the deployment based on a custom metric named requests_per_second, targeting an average value of 1000 requests per second across all pods.
Set the minimum number of replicas to 1 and the maximum to 20.
Note: Deployment named api-deployment is available in api namespace. Ignore errors due to the metric requests_per_second not being tracked in metrics-server
Is api-hpa HPA deployed in api namespace?
Is api-hpa configured for metric requests_per_second?
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: api-hpa
namespace: api
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-deployment
minReplicas: 1
maxReplicas: 20
metrics:
- type: Pods
pods:
metric:
name: requests_per_second
target:
type: AverageValue
averageValue: "1000"
12번
Configure the web-route to split traffic between web-service and web-service-v2.The configuration should ensure that 80% of the traffic is routed to web-service and 20% is routed to web-service-v2.
Note: web-gateway, web-service, and web-service-v2 have already been created and are available on the cluster.
Is the web-route deployed as HTTPRoute?
Is the route configured to gateway web-gateway?
Is the route configured to service web-service?
apiVersion: gateway.networking.k8s.io/v1beta1
kind: HTTPRoute
metadata:
name: web-route
namespace: default # 필요 시 변경
spec:
parentRefs:
- name: web-gateway
rules:
- backendRefs:
- name: web-service
port: 80
weight: 80
- name: web-service-v2
port: 80
weight: 20
13번
One application, webpage-server-01, is deployed on the Kubernetes cluster by the Helm tool. Now, the team wants to deploy a new version of the application by replacing the existing one. A new version of the helm chart is given in the /root/new-version directory on the terminal. Validate the chart before installing it on the Kubernetes cluster.
Use the helm command to validate and install the chart. After successfully installing the newer version, uninstall the older version.
Is the new version app deployed?
Is the old version app uninstalled?
helm lint /root/new-version
helm upgrade webpage-server-01 /root/new-version --namespace default --install
helm uninstall webpage-server-01 --namespace default helm uninstall webpage-server-01 --namespace default
helm install webpage-server-01 /root/new-version --namespace default
14번
Identify the starting pod CIDR network of the Kubernetes cluster. This information is crucial for configuring the CNI plugin during installation. Output the pod CIDR network to a file at /root/pod-cidr.txt.
Is Pod CIDR network correctly outputted to file?
✅ 목표: **Kubernetes 클러스터의 Pod CIDR(network 범위)**를 확인하여
/root/pod-cidr.txt 파일에 출력하는 것
✅ 1. Pod CIDR 확인 방법
방법 A: 컨트롤 플레인 노드에서 확인 (kubeadm 설치 기준)
예시 출력:
방법 B: 클러스터 전체 설정에서 확인
또는 kube-controller-manager 설정 확인:
→ --cluster-cidr=10.244.0.0/16 같이 보일 수 있음
✅ 2. 파일로 출력
위에서 얻은 CIDR 값을 파일로 저장:
또는 자동화:
✅ 3. 확인
예: 10.244.0.0/24 또는 10.244.0.0/16 같이 나와야 합니다
'따배쿠' 카테고리의 다른 글
| 따배쿠 4장 쿠버네티스 동작과정 (0) | 2023.07.15 |
|---|---|
| 따배쿠 3장 kubectl 실습 및 pod 생성하기 (0) | 2023.07.15 |

